The POP Academy is now LIVE! 🔥 Stream free courses by Kyle. Create & SEO a content silo using POP + more.
Start here
A powerful suite of tools for SEOs and content teams to help create, optimize and maintain high performing content for Google with speed and accuracy.




The average score a new user gets when they run their page through POP is low, only 37.35 / 100. But that’s great, it means there are very real SEO opportunities!
Multiply this over your entire website and you're probably sitting on a virtual Aladdin's cave of quick wins and easy traffic gains.
Writers and content teams use POP to maximize output and performance of their content and for quality assurance.
In-house SEO teams use POP to optimize important site pages, for SEO content briefs and to monitor the performance of the work they’ve done.
Agencies use POP to increase project value, validate their work to clients and extend retainers through on page performance monitoring.
Affiliate SEOs use POP to ensure their traffic pages are scientifically optimized to perform and maximize income per page.
Freelance SEOs use POP to provide enterprise level, data-driven SEO at freelancer prices. And POP reports make effortless client implementation.
POP takes the guesswork out of creating content for search engines such as Google. Input the search term and the page you want to rank and let POP create an easy to follow plan.
POP is best for creating new content, content briefs, optimizing existing content and monitoring published content to ensure it stays on top.

POP was born from the thesis that the secret to ranking is hiding in plain sight. Meaning, if you can reverse engineer what the winning competitor pages are doing and apply those same factors to your page, your rankings and traffic will increase.
The reality is not quite so simple. Not all on page factors are created equal.


Kyle Roof, POP’s inventor, holds a US patent in isolating Google ranking factors and the findings from his research are built into the POP algorithms to provide SEOs with a set of easy to follow instructions that filter the most important SEO factors and hide the rest.
Gone are the hard days of spending long hours trying to rejig your content to fit lists of keywords, NLP topics, and LSI into a specific article length while still trying to make the article sound natural.
POP AI Writer will do a much better job in a much, much shorter time. An average piece of content can now go from an Optimization Score of say 22 to a score of 100 within a few minutes.
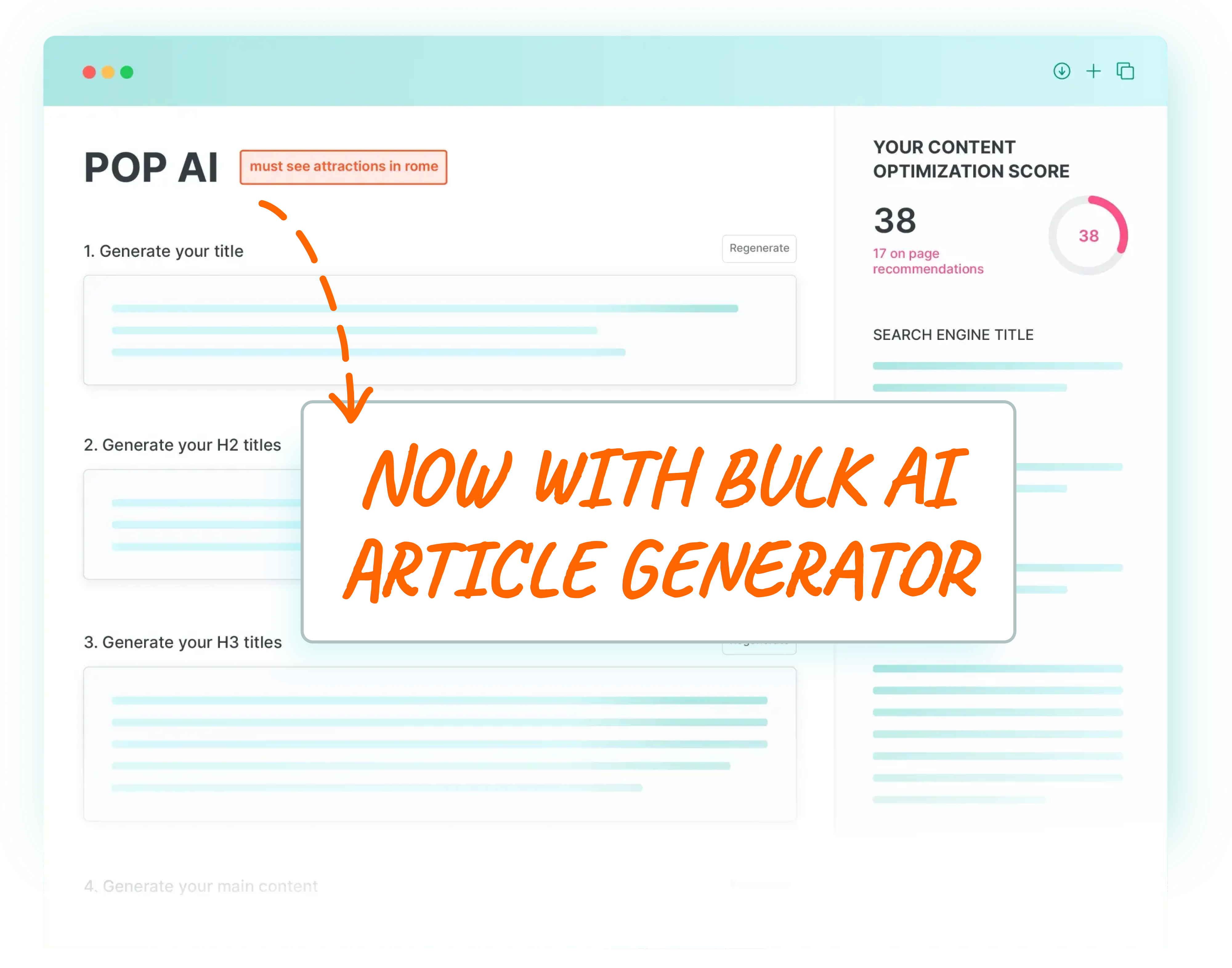
The POP Content Brief gives any writer a brief to work off to create a beautifully optimized page or improve any existing page. Just follow the simple steps from word count, keywords & variation placement, page sections and NLP suggestions with the goal to reach an Optimization Score of 100 (it’s not hard).

Integrate POP into your team's workflow. The Chrome Extension works as an overlay within Google docs as well as major website platforms, such as Wordpress and Shopify to display to-do items and page scores which update in real time.
Optimizing using the POP Content Editor is like working right on your live web page but within POP. Work on your to-do list, see your page score and even save and download the updated html from your work.

Use the Content Prompts feature to get topical suggestions for keywords, sub-headings and related sub-topics to help you easily build out a page or cluster with high relevance and topical coverage.

POP Watchdog is a one of a kind tool that protects the optimization work you’ve already done.
Watchdog will monitor your pages and alert you when something has changed due to modifications made by competitors or because of a Google update.

(Formally Advanced Mode). One of the most flexible and powerful on page SEO tools on the market. Custom is for advanced SEOs who love data, are looking for highly specific recommendations and who want to customize their own process.

Some of the strongest signals to send to Google nowadays relate to your site’s E-E-A-T, (that’s Experience, Expert, Authority & Trust). POP’s unique E-E-A-T tool displays the signals your site is sending vs your top competitors giving you a handy E-E-A-T roadmap.

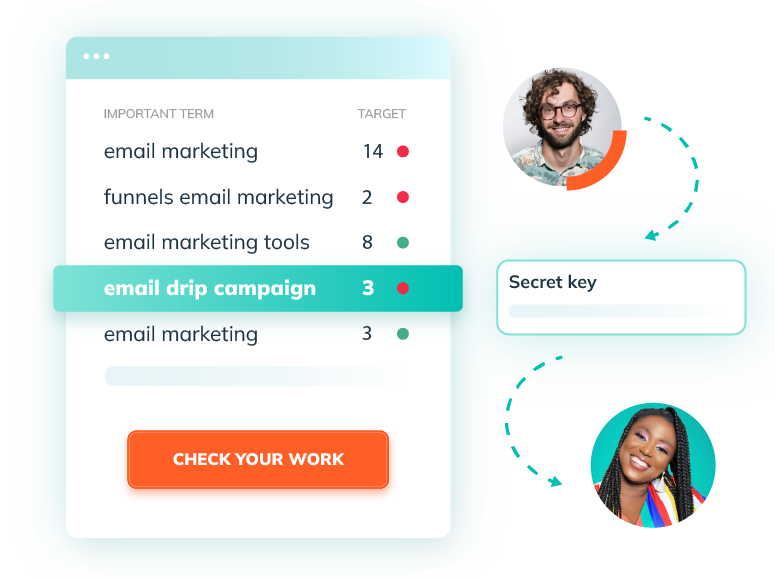
While keywords are still important, entity SEO is too. POP’s Google Entity feature displays the entities and categories Google has identified for your content alongside those of competitors then recommends terms to help Google's Knowledge Graph better understand your content.

High performing sites get their schema right and this is where many SEOs fail. POP’s schema tool makes schema easy, presenting the schemas being used by top competitors in order of importance allowing you to basically copy/paste.

A page well optimized using POP will have a higher chance of indexing and ranking faster, ranking for more search terms and generating more traffic.
Your content will also be less affected by high levels of traffic downward volatility due to Google updates.
POP helps you build the content Google is looking to reward. Produce perfectly optimized pages for Google with ease.
.png)
.png)
.png)
Up your on page SEO game by learning how to use POP to the fullest. By the end of the workshop, you will know...


"My website is just a couple of months old, so it’s in the sandbox period. I had written an article about a phrase related to sales using memberships. The first attempt at the article was nowhere near the first 5 pages on Google; in fact, I could not find it at all though it had been indexed. I ran the article through POP and it had a score of 15%. I decided to rewrite the entire thing and scored 87%. Within two days of rendering, I found my article ranking #2 for the same phrase. This is super motivating!"


POP is far from just a content optimization tool. You are about to learn how to master on-page SEO using a powerful set of tools within POP that will increase your site’s traffic and authority while making your life easier.
Works in any language and alphabet.
Get Started.png)









